AWK is another popular stream editor, just similar to SED. The basic function of awk is to search files for lines or other text units containing one or more patterns. When a line matches one of the patterns, special actions are performed on that line.
There are several ways to run awk. If the program is short, it is easiest to run it on the command line:
awk PROGRAM inputfile(s)
If multiple changes have to be made, possibly regularly and on multiple files, it is easier to put the awk commands in a script. This is read like this:
awk -f PROGRAM-FILE inputfile(s)
The most used program in awk is print, as we will see soon.
Printing selected fields
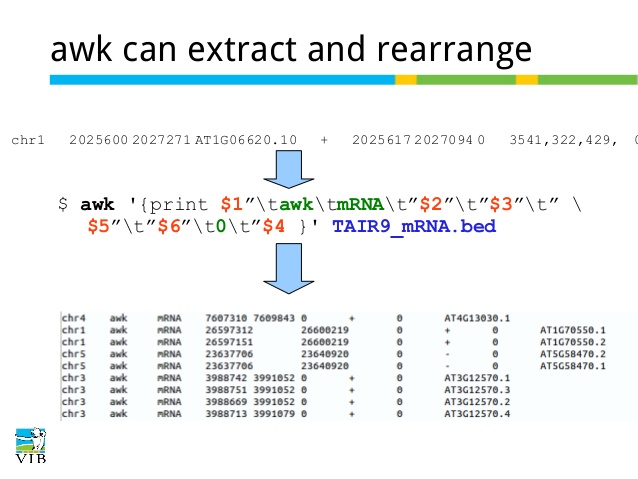
The print command in awk outputs selected data from the input file.
The variables $1, $2, $3, …, $N hold the values of the first, second, third until the last field of an input line. The variable $0 (zero) holds the value of the entire line.

To print the size ($2) and use% ($5) , use df -h | awk ‘{print $2,$5}’ .
Notice: $2,$5 : the “,” between them will separate output with a space.
Th3-Gam3 ~ # df -h | awk '{print $2,$5}'
Size Use%
3.9G 0%
786M 2%
58G 89%
3.9G 1%
5.0M 1%
3.9G 0%
Formatting fields
Without formatting, using only the output separator, the output looks rather poor. Inserting a couple of tabs and a string to indicate what output this is will make it look a lot better:
example:
Th3-Gam3 ~ # df -h | sort -rnk 5 | head -3 | awk '{ print "Partition " $6 "\t: " $5 " full!" }'
Partition /mnt/sdb6 : 99% full!
Partition /mnt/sdb5 : 97% full!
Partition /home : 89% full!
Th3-Gam3 ~ #
- we used \t to print a tab, we must use ” around text.
Formatting characters for gawk (awk)
| Sequence | Meaning |
|---|---|
| \a | Bell character |
| \n | Newline character |
| \t | Tab |
Quotes, dollar signs and other meta-characters should be escaped with a backslash.
The print command and regular expressions
A regular expression can be used as a pattern by enclosing it in slashes. The regular expression is then tested against the entire text of each record. The syntax is as follows:
awk ‘EXPRESSION { PROGRAM }’ file(s)
For example to list files that start with letter a or c and ends with .conf from /etc directory and print the 9th field :
Th3-Gam3 ~ # ls -l /etc/ | awk '/\<(a|c).*\.conf$/ { print $9 }'
adduser.conf
apg.conf
ca-certificates.conf
casper.conf
resolv.conf
Th3-Gam3 ~ #
Special patterns
In order to precede output with comments, use the BEGIN statement.
The END statement can be added for inserting text after the entire input is processed.
awk scripts
As commands tend to get a little longer, you might want to put them in a script, so they are reusable. An awk script contains awk statements defining patterns and actions.
For example: create a file called test.awk and add this lines :
BEGIN { print "*** WARNING WARNING WARNING ***" }
/\<[8|9][0-9]%/ { print "Partition " $6 "\t: " $5 " full!" }
END { print "*** Give money for new disks URGENTLY! ***" }
Run the awk command using a file :
Th3-Gam3 ~ # df -h | awk -f test.awk
*** WARNING WARNING WARNING ***
Partition / : 89% full!
Partition /mnt/sdb5 : 97% full!
Partition /mnt/sdb6 : 99% full!
Partition /home : 89% full!
*** Give money for new disks URGENTLY! ***
Th3-Gam3 ~ #
We used awk with BEGIN , END , regular expression and in a file, that is awesome !!
awk variables
As awk is processing the input file, it uses several variables. Some are editable, some are read-only.
input field separator
The default separator used by awk is space or tab , what if we need to specify different separator , use BEGIN { FS=”fs” } at beging of awk command.
for example to use “:” as a field separator :
Th3-Gam3 ~ # awk 'BEGIN { FS=":" } { print $1 "\t" $5 }' /etc/passwdroot root
daemon daemon
bin bin
sys sys
sync sync
games games
man man
output field separator
Fields are normally separated by spaces in the output. This becomes apparent when you use the correct syntax for the print command, where arguments are separated by commas.
output record separator
The output from an entire print statement is called an output record. Each print command results in one output record, and then outputs a string called the output record separator, ORS. The default value for this variable is “\n”, a newline character. Thus, each print statement generates a separate line.
To change the way output fields and records are separated, assign new values to OFS and ORS
Example :
Th3-Gam3 ~ # awk 'BEGIN { FS=":" ; OFS=" ; " ; ORS="\n-->\n" } { print $1 "\t" $5 }' /etc/passwd
root root
-->
daemon daemon
-->
bin bin
-->
sys sys
-->
sync sync
-->
games games
-->
man man
-->
number of records
The built-in NR holds the number of records that are processed. It is incremented after reading a new input line. You can use it at the end to count the total number of records, or in each output record.
for example:
Th3-Gam3 ~ # awk 'BEGIN { FS=":" ; OFS=" ; " ; ORS="\n-->\n" } { print $1 "\t" $5 "\t" "Record Number: " NR }' /etc/passwd
root root Record Number: 1
-->
daemon daemon Record Number: 2
-->
bin bin Record Number: 3
-->
sys sys Record Number: 4
-->
sync sync Record Number: 5
-->
games games Record Number: 6
-->
man man Record Number: 7
-->
Example: to list all scripts that use awk in /etc/init.d/*
grep awk /etc/init.d/*
printf program
For more precise control over the output format than what is normally provided by print, use printf. The printf command can be used to specify the field width to use for each item, as well as various formatting choices for numbers (such as what output base to use, whether to print an exponent, whether to print a sign, and how many digits to print after the decimal point). This is done by supplying a string, called the format string, that controls how and where to print the other arguments.
The syntax is the same as for the C-language printf statement; see your C introduction guide. The gawk info pages contain full explanations.
Summary
The gawk utility interprets a special-purpose programming language, handling simple data-reformatting jobs with just a few lines of code. It is the free version of the general UNIX awk command.
This tools reads lines of input data and can easily recognize columned output. The print program is the most common for filtering and formatting defined fields.
On-the-fly variable declaration is straightforward and allows for simple calculation of sums, statistics and other operations on the processed input stream. Variables and commands can be put in awk scripts for background processing.
Other things you should know about awk:
- The language remains well-known on UNIX and alikes, but for executing similar tasks, Perl is now more commonly used. However, awk has a much steeper learning curve (meaning that you learn a lot in a very short time). In other words, Perl is more difficult to learn.
- Both Perl and awk share the reputation of being incomprehensible, even to the actual authors of the programs that use these languages. So document your code!
That is it , i hope it was simple, thanks for joining me.
Enjoy !.